Building Microservices - by Sam Newman
ISBN: 978-1-491-95035-7
READ: April 20, 2016
ENJOYABLE: 9/10
INSIGHTFUL: 10/10
ACTIONABLE: 10/10
Critical Summary
I believe this book puts forward an excellent set of foundational ideas on which to evaluate decisions and trade-offs about microservices architectures.
Having case studies or references of real-world microservices architectures would greatly help guide understanding of bounded context and microservice sizing. I find my team and I wandering between fear of creating services which are too big and the fear of creating anemic, prematurely subdivided services.
What are microservices?
Microservices are small, autonomous services that work together. Many organizations have found by embracing microservices architectures, they can deliver software faster and embrace newer technologies. Microservices give us significantly more freedom to react and make decisions, allowing us to respond faster to the inevitable change that impacts all of us.
Think of microservices as a specific approach for SOA in the same way that ICP and Scrum are specifically approach for Agile software development.
Small and focused
As codebases grow it becomes difficult to know where a change needs to made, making fixing bugs and adding features more difficult. Attempts to modularize monolithic codebases tends not to be successful. Microservices take the same approach using independent services.
How small is small? Small enough and no smaller... as you get smaller, both the benefits and downsides of microservices increase.
"We seem to have a very good sense of what is too big, and so it could be argued that once a piece of code no longer feels too big, its probably small enough"
Helpful articles How Big is a Microservice and Goodbye Microservices, Hello Right Sized Services
Autonomous
Microservices can change and be deployed independently without requiring consumers to change. All communication between services are via network calls to enforce separation and avoid perils of tight coupling.
Key Benefits of Microservices
Right tool for the job - with a system composed of different services we can decide to use different technologies inside each one. allows us to pick the right tool for each job rather than having to go with a one-size-fits-all approach that often ends up being the lowest common denominator. of course, embracing multiple technologies comes with overhead, so organizations often choose to place constraints on language choices.
Resilience - In a monolithic service, if the service fails, everything stops working. With microservices, we can build systems that handle failure of other services and degrade accordingly so that if one component of a system fails the rest of the system can carry on working.
Scaling - With monolithic systems, everything has to scale together even if just one part of it is constrained in performance. With microservices, you can scale the busier services without scaling everything else.
Simpler, faster deployments - A one-line change to a million-line-long application requires the whole app to be deployed in order to deploy the change. Because deploying a million-line-long application is large-impact and high-risk, you deploy less. With microservices we can make a change to a single service and deploy it independently of the rest of the system... this allows us to deploy faster and get functionality out to customers fast.
Organizational Alignment - Large teams working on large codebases face challenges, especially with distributed teams. We know that smaller teams working on smaller codebases tend too be more productive. In addition, microservices provide greater opportunities for people to step up and own something, which can enable career growth and fulfillment for the team.
Composability - Microservices allow for reuse of functionality in different ways for different purposes. This can be especially important when think about how our customers use our app... we now need to think about desktop, web, mobile web, native, wearable, etc.
Replaceability - If you work at a medium or bigger org, chances are you are aware of some big, nasty legacy system sitting in the corner. Why hasn't it been replaced? You know why: its too big and risky a job. With our individual services being small in size, the cost to replace them with a better implementation, or even delete them altogether, is much easier to manage.
See Microservices - Not a Free Lunch for a good summary of some of the challenges and downsides of micro services.
The Architect
More than any other role, architects (at any level) can have a direct impact on the quality of the systems built, on the working conditions of their colleagues, and on their organization's ability to respond to change, and yet we so frequently seem to get this role wrong. Why is that?
The term "architect" as used in this book applies to any director-level role in software development.
The problem with calling ourselves engineers and architects
Our industry is a young one – we have only been creating software programs that run on what we recognize as computers for around 70 years. Therefore, we borrow from other professions to explain what we do. We call ourselves software "engineers" or "architects". But are we or aren't we?
Real architects and engineers have a rigor and discipline we could only dream of, and their importance in society is well understood eg. the consequences of mis-designing a highrise building. These jobs are based on a body of knowledge going back thousands of years. But what about us?
Part of us wants recognition, so we borrow names from other professions that already have the recognition we as an industry crave. But this can be doubly harmful. First, it implies we know what we are doing, when we plainly don't. Buildings and bridges do sometimes fall down, but they fall down much less than the number of times our programs will crash... making comparisons with engineers quite unfair and inaccurate. If building bridges were like programming, halfway through we'd find out that the far bank was now 50 meters father out, that it was actually mud rather than granite, and that rather than building a footbridge we were instead building a road bridge.
The term "architect" has done the most harm. The idea of someone who draws up detailed plans for others to interpret, and expects this to be carried out. In our industry, this view of the architect leads to some terrible practices. Diagram after diagram, page after page of documentation, created with a view to inform the construction of the perfect system, without taking into account the fundamentally knowable future, utterly devoid of any understanding as to how it will be to implement, or whether or not it will actually work, let alone having any ability to change as we learn more.
We put ourselves in danger of doing everyone a disservice by comparing ourselves to engineers and architects.
Unfortunately, we are stuck with the word architect for now... so best we can do is to redefine what it means in our context.
Redefining the role of the Architect
Due to the rapid change in software requirements, tools, and techniques, Architects need to shift their thinking from creating the perfect end product, and instead focus on helping create a framework in which the right systems can emerge, and continue to grow as we learn more.
Think of the role more as a town planner than architect... a town planner not say "build this specific building there"; instead a town planner zones a city and other people decide what exact buildings get created. The city changes and evolves over time and the town planner does his best to anticipate the changes, but accepts that trying to exert direct control over all aspects of what happens is futile. The number of times an architect needs to get involved to correct direction should be minimal, but if someone decides to build a sewage plant in a residential area, he needs to be able to shut it down.
Zoning for town planner = service boundaries
"Be worried about what happens between the boxes, and be liberal in what happens inside"
Architects should code - if we are to ensure that the systems we create are habitable for our developers, then our architects need to understand the impact of their decisions. At the very least, this means spending time with the team, and ideally it means spending time coding with the team too.
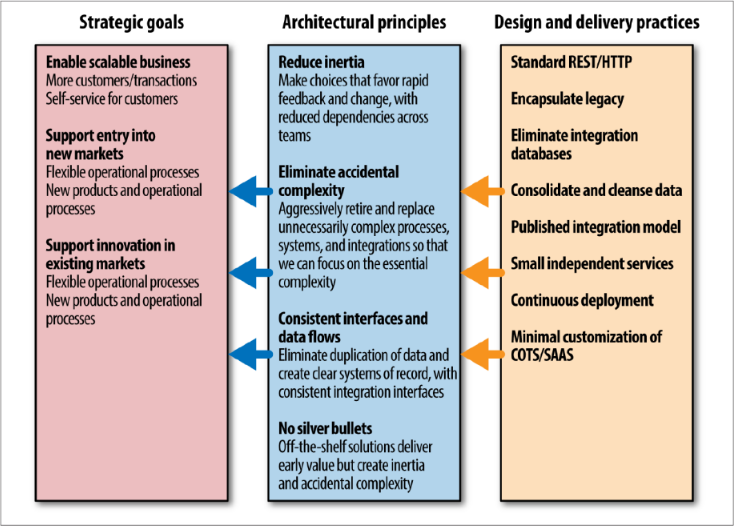
Define Strategic Goals, Principles, and Practices
Defining strategic goals and principles help guide decision-making:
- Strategic Goals - strategic goals should speak to where your company is going and how it sees itself as best making its customers happy so that you can make sure the technology is aligned with it... eg. "expand into Southeast Asia to unlock new markets" or "let the customer achieve as much as possible using self-service."
- Principles - principles are rules you have made in order to align what you are doing to a larger goal. Fewer than 10 is a good number. eg. if one of your goals as an organization is to decrease the time to market for new features, you may define a principle that sys delivery teams have full control over the lifecycle of their software to ship whenever they are ready, independently of any other team.
- Practices - practices are how we ensure our principles are being carried out They are a set of detailed, practical guidance and constraints for performing tasks, eg. coding guidelines, fact that all log data needs to be captured centrally, or that HTTP/REST is the standard integration style. Due to their technical nature, practices will often change more often than principles.
One person's principles are another's practices... that's OK. On smaller teams, combining principles and practices might be ok.
When you're working through your practices and thinking about trade-offs you need to make, one of the core balances to find is how much variability to allow in your system. One of the key ways to identify what should be constant from service to service is to define what well-behaved, good service looks like.
Good things to standardize: monitoring, interface/integration mechanisms (eg. REST, pagination, versioning), and anything related to the architectural safety of the larger system (eg. proper status codes).
How to Model Services
What makes a good service?
- Loose coupling - A change to one service should not require a change to another. A classic mistake is to pick an integration style that tightly binds one service to another, causing changes inside the services to require a change to consumers. It's good to limit the number of different types of calls from one service to another... chatty communication can lead to tight coupling as well as performance problems.
- High cohesion - We want related behavior to sit together, and unrelated behavior to sit elsewhere. We want to avoid making changes in lots of different places and deploying lots of services at once.
Bounded Context
Any given domain consists of multiple bounded context... residing within each are models that do not good to be communicated outside as well as things that are shared externally with other bounded contexts. Each bounded context has an explicit interface, where it decides what models to share with other contexts. Microservices should cleanly align to bounded contexts
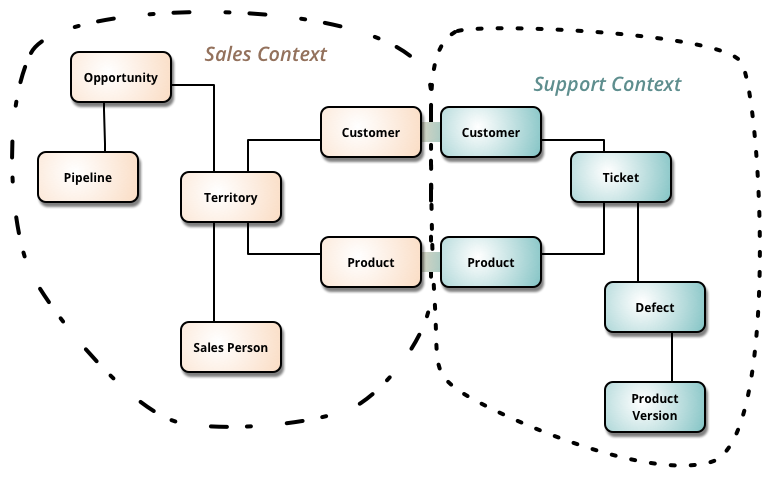
Image is from Martin Fowler's article on Bounded Context. Buzzword-free Bounded Context is also a great description.
Prematurely decomposing a system into microservices can be costly, especially if you are new to the domain (eg. greenfield development). In many ways, having an existing codebase you want to decompose into microservices is much easier than trying to go microservices from the beginning.
When you start to think about bounded contexts, do not think in terms of data that is shared, but about the capabilities contexts provide the rest of the domain. eg. The warehouse may provide the capability to get a current stock list, or the finance context may expose the end-of-month accounts or let you set up payroll for a new recruit.
Ask first, "What does this context do?", and then "what data does it need to do that?"
You'll probably identify large bounded contexts which can in turn contain further bounded contexts. First think in terms of larger, coarser-grained contexts, and then evaluate the benefits of subdividing further... eg. to align with org structure, simplify testing.
Integration
Problem with shared databases:
- If you change your schema, it breaks consumers
- Consumers are also bound to using that database technology
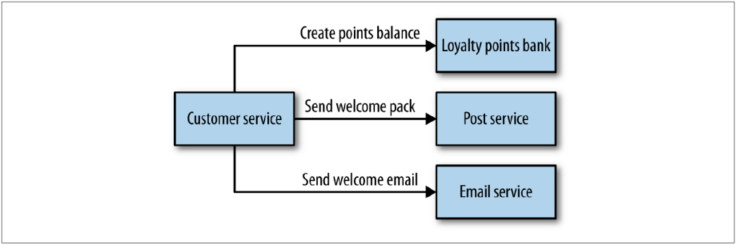
Orchestration vs Choreography
With orchestration, we rely on a central brain to guide and drive the process. With choreography, we inform each part of the system of its job, and let it work out the details.
Orchestration is simple and easy to reason about... we can use synchronous requests to know if things worked straightaway.
The downside to this approach is that the customer service can become too much of a governing authority... it can become a hub in the middle of a web, and a central point where logic lives
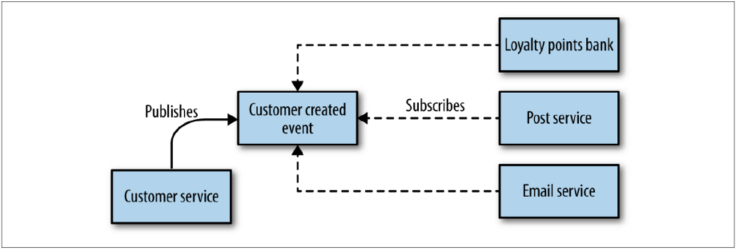
With a choreographed approach, the customer service emits events and the other services subscribe to them and react asynchronously. This approach is significantly more decoupled, but the downside is that the explicit view of the business process (creating points balance, sending welcome pack, sending welcome email)is now only implicitly reflected in our system.
This means additions work is needed to ensure that you can monitor and track that the right things have happened. Use correlation IDs to trace requests across process boundaries (see later section).
In general, I have found that systems that tend more toward the choreographed approach are more loosely coupled, and are more flexible and amenable to change, although you do need to do extra work to monitor and track the processes across boundaries. I have found most heavily orchestrated implementations to be extremely brittle, with a higher cost of change.... I strongly prefer aiming for a choreographed system, where each service is smart enough to understand its role in the whole dance.
Perils of DRY and code reuse
If your use of shared code leaks outside your service boundaries, you have introduced a potential form of coupling. Instead of using a shared library, consider copy and pasting it into each new service to ensure coupling doesn't leak in (pg. 59)
My general rule of thumb: don't violate DRY within a micro service, but be relaxed about violating DRY across all services. The evils of too much coupling between services are far worse than the problems caused by code duplication.
One potential exception is client libraries (pg. 59) which many companies use or even require in order to make it easy to use services and get up and running.
Versioning
The best way to reduce the impact of making breaking changes is to avoid making them in the first place.
Poster's Law / robustness principle: "Be conservative in what you do, be liberal in what you accept from others"
User Interfaces
Think of user faces as compositional layers–places where we weave together the various strands of capabilities we offer.
One strategy is to have the UI interact directly with different services... however, this can lead to chatty communication (lots of service calls per screen), and if another team is creating the UI, this means coupled changes where a change requires changes across multiple teams.
Another common strategy is having a single monolithic API gateway that handles calls to/from UIs... this can result in problems as the gateway becomes stuffed with more and more logic and managed by separate teams, and user interfaces can't be deployed independently.
A strategy that works well is to restrict the use of these backends to one specific user interface, referred to as backends for frontends. It allows the team focusing on any given UI to also handle its own server-side components. You can see these backends as part of the user interface that lives on a server. Important: the business logic should stay in the services themselves. The BFFs should only contain behavior specific to delivering a particular user experience.
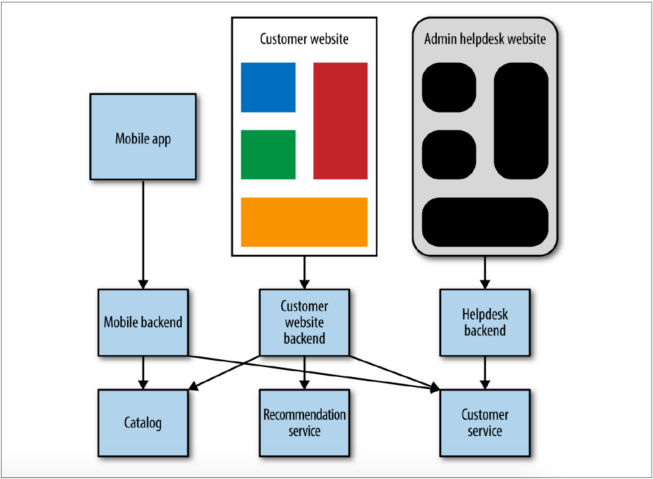
Integrating with Third-Party Software
Build if it is unique to what you do, and can be considered a strategic asset; buy if your use of the tool isn't that special.
eg. Most organizations tend to buy CMSes off the shelf, but the Guardian builds their own.
Challenges of COTS Software
With COTS (commercial off-the-self) software you cede control to an outside party eg. how you can integrate, what programming language you can use to extend the tool, ability to store configuration in version control and rebuild from scratch
Customization
Many tools that enterprise organizations purchase sell themselves on their ability to be heavily customized just for you. Beware... often, due to the nature of the tool chain you have access to, the cost of customization can be more expensive than building something bespoke from scratch!
I have worked with multiple CMSes that by design do not support continuous integration, that have terrible APIs, and for which even a minor-point upgrade in the underlying tool can break any customizations you have made.
This is easy to overlook. As an example, while Salesforce quickly gives you a CRUD database application, the cost of adding some integration or customization by bringing in Salesforce developers can quickly outweigh what it would cost to build a custom CRUD app in Rails that is much easier to integrate and customize.
Integration
Another challenge is integration... with microservices you want to be very careful and standardized in how you integrate between services, but with third-party systems you are beholden to whatever means of integration they support (eg. having consumers coupled to Salesforce object schema changes, having to use SOAP).
A solution is to create a facade service that sits in between your consumers and the third-party system.
The Solution
Bring the integration and customization work back on to your terms by doing any customizations on a platform you control, and limiting the number of different consumers of the tool itself.
Example: The multirole CRM system
CRMs, typified by vendors like Salesforce or SAP, are rife with examples of tools that try to do everything for you. This can lead to the tool itself becoming a single point of failure, and a tangled knot of dependencies.
One organization realized that it was using a CRM tool for a lot of things, but not getting the value of the increasing costs with the platform. At the same time, multiple internal systems were using less-than-ideal CRM APIs for integration.
The solution for wrestling back control and lay the groundwork for migration was to create well-modeled facade services:
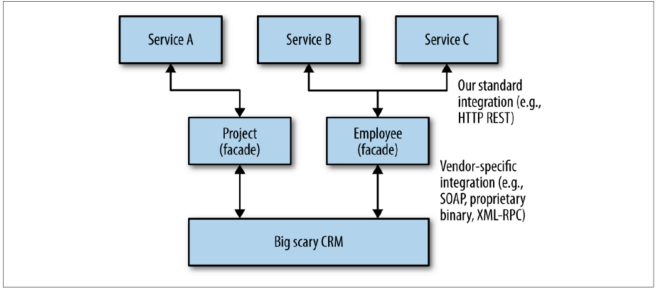
Splitting the monolith
Reasons to split
- Pace of change - perhaps we know that we have a load of changes coming up soon in how we manage inventory. If we split out the warehouse seam as a service now, we could change that service faster, as it is a separate autonomous unit.
- Team structure - it would be great to split out the code so separate teams (perhaps located in different geographical regions) can take full ownership
- Technology - Perhaps the team has been spiking on some new algorithms using a library in Clojure... if we could split out the recommendation code into a separate service, it would be easy consider building an alternative implementation against.
How to split
See pages 83 - 90
Transactions
The most common algorithm for handling distributed transactions is the two-phased commit (transaction manager first checks with all participants to see if their transactions can go ahead, and if so, tells them all to go ahead).
Eventual consistency - rather than using a transactional boundary to ensure that the system is in a consistent state when the transaction completes, we accept that the system will get itself into a consistent state at some point in the future,
Distributed transactions are hard to get right... when you encounter business operations that occur within a single transaction, try to find ways to make them not need to and instead rely on the concept of eventual consistency.
Reporting
Reporting typically needs to group together data from systems across multiple parts of the organization.
Data Retrieval via Service Calls
APIs exposed by various micro services may well not be designed for reporting use cases... eg a Customer service wouldn't necessarily expose an API to retrieve all customers. In addition, regularly fetching large volumes of data over service calls is a slow operation.
Data Pumps
Since retrieving data by HTTP calls is inefficient, an alternative is to have a standalone program directly access the database of the service that is the source of data and periodically pumps it into a reporting database. This is a notable exception to the rule of avoiding having programs integrate on the same database – in this case the downsides of coupling are more than mitigated by making reporting easier.
We can reduce the problems with coupling to the services schema by having the same team math manages the service also manage the pump. They should be version-controlled and built/deployed together. The reporting schema should be completely decoupled from the services' schemas and should be treated as a published API that is hard to change.
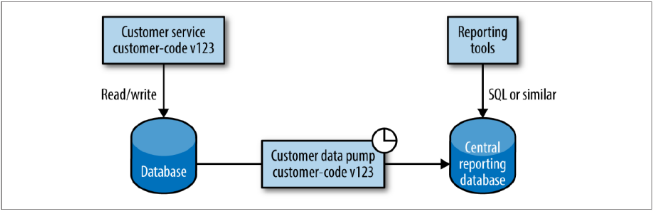
An alternative strategy is to use materialized views to expose only the reporting schema:
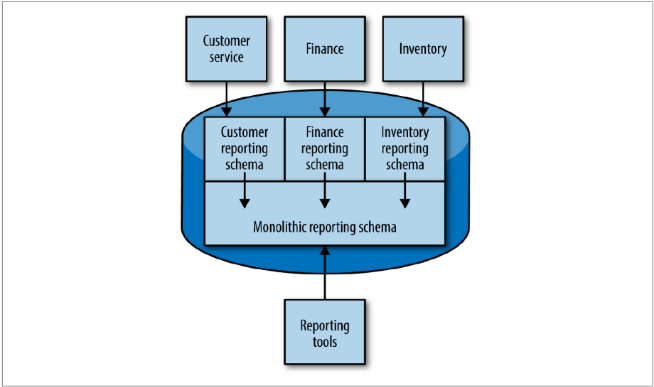
Event Data Pump
Another option is to write an event subscriber that pumps data into the reporting database.
Benefits:
- Eliminates any possible coupling to the underlying database of the source microservice and makes it easier for it to be managed by a separate group from the team managing the source microservice.
- Allows data to flow faster to the reporting system rather than relying on a regular scheduled data dump.
The main downside is that all required information must be broadcast as events, and it may not scale as well as a data pump for larger volumes of data that has the benefit of operating directly at the database level.
Virtualization
Single service per host is preferred, however if there are cost or management implications, virtualization allows us to slice up a physical server into separate hosts, each of which can run different things.
Slicing up machines into numerous VMs isn't free. Think of our physical machine as a sock drawer. If we can put lots of wooden dividers into our drawer, can we store more socks or fewer? The answer is fewer – the dividers themselves take up room too.
Traditional virtualization
Type 2 virtualization - Implemented by AWS, VMWare, Sphere... Vas run on physical infrastructure that has a host operating system, on which we run a hypervisor that (1) maps resource like CPU and memory from the virtual host to the physical host, (2) acts as a control layer for manipulating the virtual machines themselves. The hypervisor uses resources, and the more virtual machines it manages, the more resources it needs.
Vagrant allows you to define a set of VMs in a text file, along with how the VMs are networked together and which images the VMs should be based on.
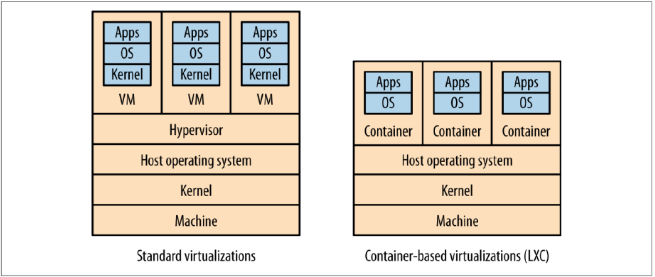
Linux Containers
Linux has an alternative to virtualization. Rather than having a hypervisor to segment and control separate virtual hosts, Linux containers instead create a separate process subtree that is managed by the Linux kernel. Operating systems running on containers must share the same kernel.
We save resources by not needing a hypervisor and can have many more of them running on the same hardware than would be possible with VMs. Linux containers are also much faster to provision (a few seconds vs a few minutes for VMs).
Handling and configuring containers is complex and time-consuming.... luckily, Docker can handle much of the work for you. For dev/testing purposes, you can have a single VM booted up in Vagrant that runs a Docker instance to handle multiple services.
Testing
- Unit tests - Tests for classes and methods to give us very fast feedback about whether our functionality is good. Tests can be important to support refactoring of code, allowing us to restructure our code as we go, knowing that our small-scoped tests will catch us if we make a mistake. Used in TDD.
- Service tests - Tests which bypass the user interface and test services directly (in a big Rails app, this means controller unit tests).
- End-to-end tests - Tests which run against your entire system, driving a UI through the browser. When they pass, you have a high degree of confidence that the code being tested will work in production.
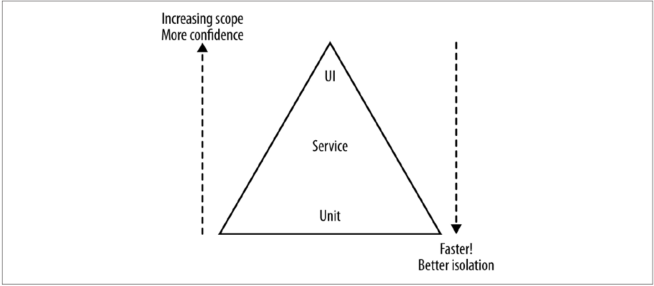
As you go up the pyramid, the test scope increases, as does our confidence that the functionality being tested works. On the other hand the feedback cycle time increases as the tests take longer to run, and when a test fails it can be harder to determine which functionality has broken.
As you go down the pyramid, in general the tests become much faster, so we get much faster feedback cycle. We find broken functionality faster, our continuous integration builds are after, and we are less likely to move on to a new tasks before finding out we have broken something.
How many of each type of tests do you want? A good rule of thumb is that you want an order of magnitude more tests as you descend the pyramid.
End-to-end tests vs Consumer-driven Contracts
Avoid the need for end-to-end tests wherever possible by using consumer-driven contracts. Consumer-driven contracts are expectations by consumers of a producer, captured in code form as tests. Each consumer team should collaborate with the producer team to create the tests, and each consumer should have its own set of tests.
End-to-end tests may form a useful safety net, especially in environments where the appetite to learn in production is low.
From speaking to people who have been implementing micro services at scale, I have learned that most of them over time remove the need for end-toned tests in favor of tools like CDCs and improved monitoring.
Blue/green deployment and Canary releasing
- smoke-test suite - a collection of tests designed to be run against newly deployed software to confirm that the deployment worked
- blue/green deployment - two copies of our software deployed at a time, but only one version of it receiving real requests (by switching over dos or load-balancing config)
- canary releasing - verifying newly deployed software by direction amounts of production traffic against the system to see if its good
Mean Time to Repair over Mean Time Between Failures
Sometimes expending the same effort into getting better at remediation of a release can be significantly more beneficial than adding more automated functional tests. This is often referred to as the trade-off between optimizing for mean time between failures (MTBF) and mean time to repair (MTTR).
Techniques to reduce the time to recovery can be as simple as fast rollbacks coupled with good monitoring.
In addition to MTBF and MTTR, don't forget about other trade-offs such as getting something out now to prove the idea or the business model before building robust software. In an environment like this, testing may be overkill, as the impact of not knowing if your idea works is much higher than having a defect in production.
Monitoring
In my opinion, monitoring is one area where standardization is incredibly important.
The secret to knowing when to panic and when to relax is to gather metrics about how your system behaves over a long-enough period of time that clear patterns emerge. * Track inbound response time at a bare minimum. Follow with error rates and then application-level metrics. * Log into a standard location, in a standard format if possible. Have a single query able tool for aggregating and storing logs * Monitor hosts (eg. CPU/memory) so you can track down rogue processes and do capacity planning * Understand what requires a call to action, and structure alerting and dashboards accordingly * Monitor product metrics like the number of time an action is performed or a page is viewed. This can help inform whether new changes are improving or hurting users. * Strongly consider standardizing on the use of correlation IDs (read more below)
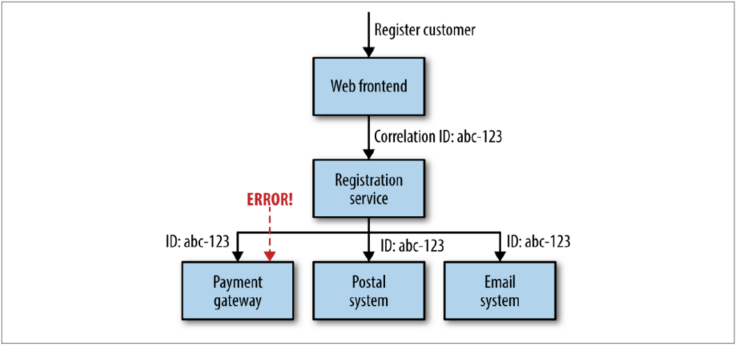
Correlation IDs
With a large number of services interacting to provide any given end-user capability, a single initiating call can end up generating multiple more downstream service calls... which amens it very difficult to trace a chain of logs upstream like we do with a stack trace.
One approach that can be useful here is to use correlation IDs. When the fist call is made, you generate a GUID for the call that is then passed along to all subsequent calls and can be put into your logs in structured way.
Conway's Law and Organizational Design
Any organization that designs a system will inevitably produce a design whose structure is a copy of the organization's communication structure.
"if you have four groups working on a compiler, you'll get a 4-pass compiler"
In Exploring the Duality Between Product and Organization Architectures, the authors found that more loosely coupled organizations created more modular, less coupled systems, whereas the more tightly focused organization's software was less modularized.
Amazon saw the benefits of teams owning the whole lifecycle of the systems they managed... and that small teams work faster than large teams... this led to its two-pizza teams rule where no team should be so big that it can't be fed with two pizzas.
Geographic boundaries between people involved with the development of a system can be a great way to drive when services should be decomposed. You should look to assign ownership of a service to a single, colocated team who can keep the cost of change low.
Complex systems with high costs of coordinating change result in less changes and less ownership... resulting in large, hard-to-maintain codebases.
Service Ownership
Having teams fully own one or more services pushes the decisions to the people best able to make them, giving the team both increased power and autonomy, but also making it accountable for its work.
"service ownership" = from sourcing requirements to building, deploying, and maintaining the application.
I've seen too many developers hand their system over for testing or deployment phases and think that their work is done at that point.
Shared Services
Many teams adopt a model of shared service ownership for a variety of reasons:
- Too hard to split - one of the reasons you may find yourself with a single service owned by more than one team is that the cost of splitting the service is too high, or perhaps your organization might not see the point of it
- Feature teams - feature teams are an antipattern in a micro services environment because they constitute teams organized around technical boundaries instead of business boundaries
- Delivery bottlenecks - shifting developers from working on one service to another in order to complete a feature faster
Internal Open Source
The internal open source model can make a lot of sense when you can't find a way past having a few shared services, particularly to avoid bottlenecks.
Like with normal open source, internal open source should have a group of trusted committers (the core team) and untrusted committers (people from outside the team submitting changes). The core team reviews and approves changes.
The less mature a service is, the harder it will be to allow people outside the core team to submit patches (without a certain amount of code in place, it can be difficult to produce good submission).
Bounded Contexts and Team Structures
Teams should be aligned to bounded contexts too...
- easier to grasp domain concepts within a bounded context since they are interrelated
- services within a bounded context are more likely to be services that talk to each other, making coordination easier
- in terms of how the delivery team interacts with the business stakeholders, it becomes easier for the team to create good relationships with the one or two experts in that area
Microservices at Scale
Failure is inevitable... assume failure will happen and build this thinking into everything you do.
Systematically evaluate how much failure your applications can tolerate, and then address them.
Architectural safety measures:
- Timeouts - Put timeouts on all network calls. Log when timeouts occur, look at what happens, and change them accordingly. Wait too long to decide a call has failed, and you can slow the whole system down. Time out too quickly, and you'll consider a call that might have worked as failed.
- Circuit breakers - After a certain number of requests have failed, the circuit breaker is blown. All further requests fail fast while the circuit breaker is in its blown state... after a certain period of time, the client sends a few requests through to see if the downstream service has recovered, and if it gets enough healthy responses it resets the circuit breaker. Circuit breakers can also be used as a tool for taking a service down to do maintenance.
- Bulkheads - A bulkhead is a part of the shift that can be sealed off to protect the rest of the ship. In software architecture, there are lots of different bulkheads we can consider, eg. separation of concerns.
See Heroku's article on circuit breakers
"design for ~10x growth, but plan to rewrite before ~100x"
CAP Theorem
CAP theorem tells us that three things trade off against each other in distributed systems–consistency, availability, and partition tolerance–and that we can only guarantee two of the three attributes for when any one part of the system is lost or fails:
See Brewer's update on CAP Thorem, CAP Twelve Years Later: How the "Rules" Have Changed as well as A plain english introduction to CAP Theorem
- Consistency = All nodes see the same data at the same time
- Availability = Every request receives a response
- Partition Tolerance = The system continues to operate... in other words, no set of failures less than total network failure is allowed to cause the system to respond incorrectly.
AP systems scale more easily and are simpler to build... CP system will require more work due to challenges in supporting distributed consistency
A simple example of consistency vs availability: two services that both need information about users... one method is to use a message queue to sync over changes to users in one system to the other... another is to do API lookups from one service to the other... the former ensures availability while the latter ensures consistency.